
英文“index”。汉语翻译“索引”,在汉语词典中的解释如下:
Wiki:索引是一个汉语词语,读音为suǒ yǐn。指检寻图书资料的一种工具,将书刊中的内容或项目分类摘录,标明页数,按一定次序排列,附在一书之后或之前,或单独编印成册,以便读者查阅,旧称通检或备检;
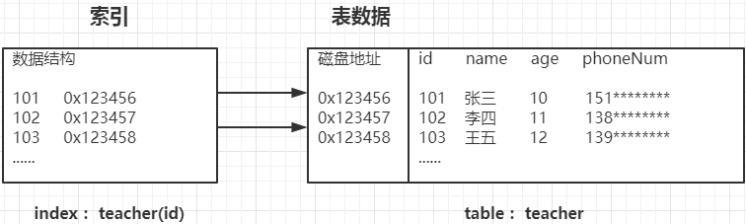
在查询新华字典等数据繁多的书籍时,我们通常会查询目录,找到对应字的页码,再根据页码找到需要具体的字义。顾名思义,索引就是类似书籍目录的功能,将数据进行分类排序,将磁盘上的线性数据结构化。方便我们能快速找到数据。
MySQL数据库逻辑架构
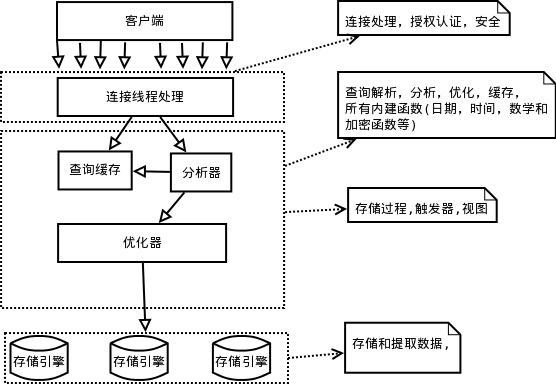
如上架构图所示,索引属于最下层,存储引擎层,每个存储引擎实现索引的方式都各不相同。以下的所有内容都基于innodb存储引擎展开讨论。
特别说明,现代固态硬盘有着完全不同于传统磁盘的优越随机IO性能。数据库的全表扫描效率大于传统的磁盘。但是索引的原则依然成立,只是全表扫描对固态硬盘的的性能影响没有传统磁盘那么糟糕。
索引基础
索引的优缺点
优点
1.索引大大减小了服务器需要扫描的数据量
2.索引可以帮助服务器避免排序和临时表
3.索引可以将随机IO变成顺序IO
4.索引对于InnoDB。可以使事务可以锁更少的行。
缺点
1.虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存索引文件。
2.建立索引会占用磁盘空间的索引文件。一般情况这个问题不太严重,但如果你在一个大表上创建了多种组合索引,索引文件的会膨胀很快。
3.如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。对于非常小的表,大部分情况下简单的全表扫描更高效;
因此应该只为最经常查询和最经常排序的数据列建立索引。
MySQL里同一个数据表里的索引总数限制为16个。
按照底层数据结构分类
B-Tree索引
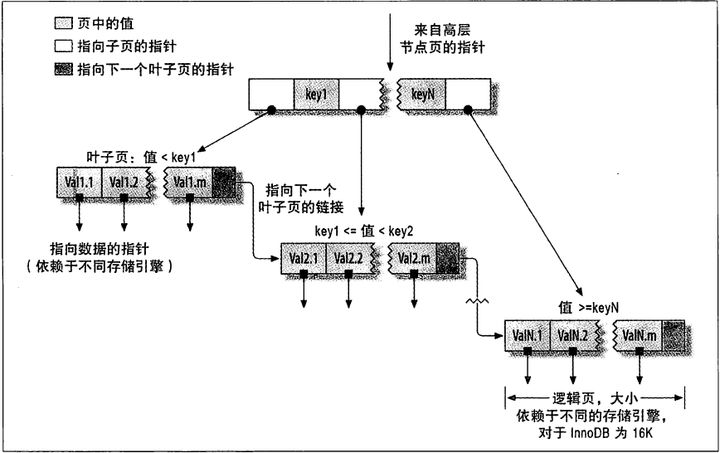
MySQL的B树索引的底层结构使用b+树实现。具体结构在B树文章中有说明。
B树可以对<,<=,=,>,>=,BETWEEN,IN,以及不以通配符开始的LIKE使用索引。B树索引检索的值都是按照顺序存储的,层树相同,且最下层形成一个链表,非常适合范围查询。
例子如下:
1 | CREATE TABLE People ( |
如上表结构,其组合索引包含表中每一行的last_name、first_name和dob列。索引结构如下所示。

上图的数据节点都是按照last_name、first_name,dob排序的。所以在使用此索引时,必须按照排序的顺序进行检索方能使用该索引,即按照(last_name)(last_name,first_name)(last_name、first_name,dob)三种查询方式。如果不是按照索引的最左列开始查找,则无法使用索引。
1.查询必须从索引的最左边的列开始,否则无法使用索引。例如,你不能直接利用索引查找在某一天出生的人。
2.不能跳过某一索引列。例如,你不能利用索引查找last name为Smith且出生于某一天的人。
3.存储引擎不能使用索引中范围条件右边的列。例如,如果你的查询语句为WHERE last_name=”Smith” AND first_name LIKE ‘J%’ AND dob=’1976-12-23’,则该查询只会使用索引中的前两列,因为LIKE是范围查询。
规范
【强制】:⑦不允许使用 % 开头的模糊查询
解读:根据索引的最左前缀原理,%开头的模糊查询无法使用索引,可以使用 ES 来做检索。“全模糊查询无法使用 INDEX,应当尽可能避免”—引自《数据库设计开发规范-阿里》;
【强制】在建立索引时,多考虑建立联合索引,并把区分度最高的字段放在最前面
解读:区分度高,有利于索引树性能好,查询的时候效率更高;
例如列userid的区分度可由select count(distinct userid) 计算出来。(干货,可直接套用计算)
该索引对以下的查询有效:
1.匹配全值(Match the full value):对索引中的所有列都指定具体的值。例如,上图中索引可以帮助你查找出生于1960-01-01的Cuba Allen。
2.匹配最左前缀(Match a leftmost prefix):你可以利用索引查找last name为Allen的人,仅仅使用索引中的第1列。
3.匹配列前缀(Match a column prefix):例如,你可以利用索引查找last name以J开始的人,这仅仅使用索引中的第1列。
4.匹配值的范围查询(Match a range of values):可以利用索引查找last name在Allen和Barrymore之间的人,仅仅使用索引中第1列。
5.匹配部分精确而其它部分进行范围匹配(Match one part exactly and match a range on another part):可以利用索引查找last name为Allen,而first name以字母K开始的人。
6.仅对索引进行查询(Index-only queries):如果查询的列都位于索引中,则不需要再多一次I/O回读元组。(覆盖索引:索引的叶子节点中已经包含要查询的数据,那么就没有必要再回表查询了,如果索引包含满足查询的所有数据,就称为覆盖索引。)
1. 哈系索引
哈系索引实现对数据列值计算哈希值实现的索引,类似于HashMap。在MySQL中,只有Memory引擎显式支持哈系索引。哈系索引和R-Tree索引不再探讨,有兴趣的可以研究。
根据数据与索引的存储关联性划分
根据数据与索引的存储关联性,可以分为聚簇索引和非聚簇索引(也叫聚集索引和非聚集索引)。聚簇索引也叫簇类索引,是一种对磁盘上实际数据重新组织以按指定的一个或多个列的值排序。整个简洁的说法,这俩的区别就是索引的存储顺序和数据的存储顺序是否是关系的,有关就是聚簇索引,无关就是非聚簇索引。具体实现方式根据索引的数据结构不同会有所不同。
举个例子:牛津高阶英语词典。书的侧面有26个英文字母的索引。找到了索引也就找到了词的位置,这个叫聚簇索引。而普通书籍将目录单独提到书内容的最前方。使用页码作为指针连接到具体的内容。这个叫非聚簇索引。

聚簇索引
聚簇索引有数据和键值紧密的存储在一起,找到了键值也就找到了数据,节点的排列顺序和实际的物理存储顺序一致等典型特征。无法同时将数据行放在两个不同的地方,所以一张表只能有一个聚簇索引,通常是主键的索引,这也就是为什么使用主键查询是最快的。如果一张表没有显式声明主键,选用唯一且非空约束的一列。都没有数据库就会隐式的声明一个主键。
innodb建表完成后只有一个数据文件.ibd,单表表空间文件,每个表使用一个表空间文件(file per table),存放用户数据库表数据和索引。表示此时索引和数据是在一起的,是聚簇索引。
而MyISAM存储引擎在建立新表时会创建两个文件:.MYD文件:即MY Data,表数据文件
和.MYI文件:即MY Index,索引文件。数据和索引分开,是非聚簇索引。
InnoDB聚簇索引结构:
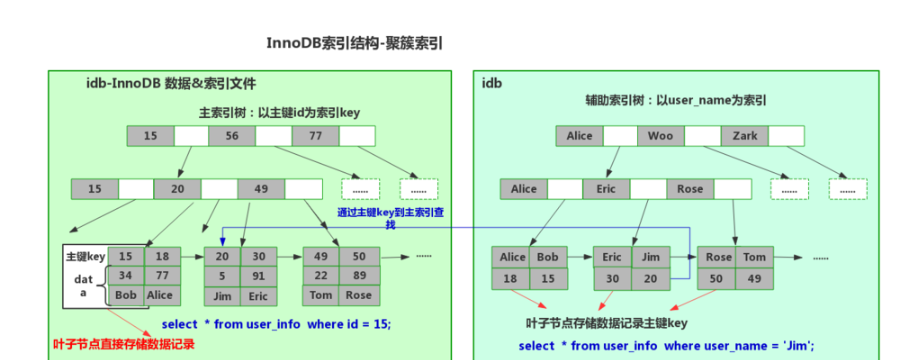
InnoDb支持行级锁,但是与oracle不同的是,innodb的行级锁是对索引上的索引项进行加锁的。所以只有通过索引查询的数据,innodb才会使用行级锁。
优点
1.将相关的数据保存在一起,这样只需要在磁盘上读取少量的数据页即可获取需要的数据。如果没有使用聚簇索引,查询一次数据可能需要大量的IO。
2.数据访问更快,聚簇索引的索引和数据保存在一起,在传统磁盘上可以避免磁头寻道等耗时动作。
3.使用覆盖索引扫描的查询就可以直接使用页节点的主键值。
缺点
1.如果数据全部放在内存中,使用聚簇索引的价值就不大了。
2.插入速度严重依赖插入顺序,按照主键的顺序插入是最快的。
3.更新聚簇索引的代价很高,InnoDB会移动每个更新行数据的位置。可能会导致页分裂的情况发生,页分裂操作会导致表占用更多的空间。
4.同样是导致页分裂操作的时候,全表扫描会变慢。
5.非聚簇索引查询数据时需要两次索引查找,而不是一次。
这也是为何在新建数据表时,会推荐建立自增 id 作为主键,同时 id 自增确保业务层面上的无意义。确保主键 ID 业务上无意义很重要,因为它确保你再已生成记录的主键 ID,是不会被 update 的。如果是随机主键或者频繁更新主键的话,就会存在数据页频繁断裂,B + 树不饱和的情况(原因:聚簇索引是按顺序进行排序的)。而如果设置主键是自增,那么每一次都是在聚集索引的最后增加,当一页写满,就会自动开辟一个新页,不会有聚集索引树分裂这一步,效率会比随机主键高很多。这也是很多建表规范要求主键自增的原因。
简单场景可以使用AUTO_INCREMENT进行主键自增,但是使用AUTO_INCREMENT进行主键自增在高并发场景下有致命缺点。
非聚簇索引
非聚簇索引也叫做二级索引,非聚簇索引的索引结构和数据没有放在一起,所以使用非聚簇索引查询数据时,会首先通过索引查询到了主键ID,再进行一次回表查询,通过索引找到的id再次通过聚簇索引找到真正的数据行。
索引使用
索引实现在存储引擎层,所以不同的存储引擎有不同的实现原理,本文基于innodb存储引擎展开讨论。
普通索引
创建
CREATE INDEX indexName ON table(field(length));
ALTER table ADD INDEX [indexName] ON (field(length))
删除
DROP INDEX [indexName] ON table;
唯一索引
唯一索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
创建
CREATE UNIQUE INDEX indexName ON table(field(length));
ALTER table ADD UNIQUE INDEX [indexName] ON (field(length))
删除
DROP INDEX [indexName] ON table;
主键索引
特殊的唯一索引,不允许有空值。一个表只能有一个主键。建表的时候指定PRIMARY KEY(ID)。
组合索引
根据复合查询条件创建的索引。
例如下面的SQL。
select * from user where username = '张三' and age = '20' city = '深圳' and
在普遍的场景下,用户名是最常用的一个搜索字段 ,其次是年龄,在然后是城市。所以可以建立一个组合索引。
ALTER TABLE user ADD INDEX name_age_city (username,age,city);
建立这样的组合索引,根据B+树的最左前缀的结果,是相当于分别建立了下面三组组合索引:
usernname,age,city
usernname,age
usernname
所以下面两个查询会用到索引
SELECT * FROM user WHERE username=”admin” AND age=20
SELECT * FROM user WHERE username=”admin”
SELECT * FROM user WHERE username like “ad%”
而下面两个则不会用到:
SELECT * FROM user WHERE age=20 AND city=”深圳”
SELECT * FROM user WHERE city=”深圳”
SELECT * FROM user WHERE username like “%ad”
SELECT * FROM user WHERE username like “ad%” and age = 20
索引设计
MySQL的B-Tree只对<,<=,=,>,>=,BETWEEN,IN,以及不以通配符开始的LIKE才会使用索引。所以在中间的解析器和优化器完成的函数表达式是不使用索引的。
不使用索引场景
MySQL不使用索引的场景汇总如下:
1.查询的列中使用了 != 比如 select id,name,age from student where id != 2;
2.查询的列中使用了函数操作,比如 pow(id,2) 对 id 做平方这种函数表达式,也不会用到索引
3.如果条件中有 or,即使其中有部分条件带索引也不会使用(这也是为什么尽量少用or的原因),如果or的所有条件列都加了索引,才会使用。
4.联合索引中即使满足最左前缀原则,但是第一个条件带了范围查询,那么也不会用到索引
5.存在索引列的数据类型隐形转换,则用不上索引,比如列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
6.如果 MySQL 估计使用全表扫描要比使用索引快,则不使用索引
规范
【建议】:④避免在 WHERE 条件的属性上使用函数或者表达式
解读:MySQL 无法自动解析这种表达式,无法使用到索引。
【建议】:⑥应尽量避免在 WHERE 子句中使用 or 作为连接条件
解读:根据情况可以选择使用 UNION ALL 来代替 OR。
【建议】:⑧在 Where 中索引的列不能某个表达式的一部分,也不能是函数的参数
解读:即是某列上已经添加了索引,但是若此列成为表达式的一部分、或者是函数的参数,MySQL 无法将此列单独解析出来,索引也不会生效。
一般来说,如果SQL中出现了WHERE和JOIN,则关键列需要加索引。
如:
SELECT t.Name FROM table1 t LEFT JOIN table2 m ON t.name=m.username WHERE m.age=20 AND m.city='深圳'
以上SQL则需要在age和city两个字段加索引,且username作为连接的条件列,也需要加索引。
索引使用技巧
索引字段使用数值类型比字符串快
在索引树的增删改查中,数值型只需比较一次即可,字符型需要比较多次。
字段值不要让默认值为NULL
规范
【强制】:⑦ 必须把字段定义为 NOT NULL ,业务可以根据需要定义DEFAULT值
解读:这里跟oracle对于NULL内部处理不同,特别是索引列,千万要注意这条强制规则,原因:
- NULL 的列使索引/索引统计/值比较都更加复杂,对 MySQL 来说更难优化。
- NULL 这种类型 MySQL 内部需要进行特殊处理,增加数据库处理记录的复杂性;同等条件下,表中有较多空字段的时候,数据库的处理性能会降低很多。
- NULL值需要更多的存储空,无论是表还是索引中每行中的 NULL 的列都需要额外的空间来标识。
目前新运控oracle库里面,索引为空的情况较为严重,各位同事转换过程要提高警惕。
注意重复/冗余的索引、不使用的索引
对于重复/冗余、不使用的索引:可以直接删除这些索引。因为这些索引需要占用物理空间,并且也会影响更新表的性能。
如果对大的文本进行搜索,使用全文索引而不要用使用 like ‘%…%’
大字段索引时使用前缀索引代替所有字符的索引,太长的字符串会拖慢索引的速度。
规范
【强制】:⑥在较长 VARCHAR 字段,例如VARCHAR(100) 上建立索引时,应指定索引长度,没必要对全字段建立索引,根据实际文本区分度决定索引长度即可
解读:索引的长度与区分度是一对矛盾体,一般对字符串类型数据,若长度为 20 的索引,区分度会高达 90% 以上,则可以考虑创建长度例为 20 的索引,而非全字段索引。
例如,可以使用 SELECT COUNT(DISTINCT LEFT(BIZ_CODE, 20))/COUNT(*) FROM TX_META_CODE;来确定 BIZ_CODE字段字符长度为 20 时文本区分度。(干货,可直接套用计算)
创建表索引,指定索引长度:
CREATE INDEX index_name ON table_name (column_name(length), clolumn_name(length)…);
目前新运控Oracle版本,各个模块各表索引字段长度都比较大,特别是在varchar字段上,迁移到mysql后,立即会出现如下两种情况的报错:
1 | “Error : Specified key was too long; max key length is 767 bytes” |
